好久沒寫水文了,新年第一篇水文總得寫一下,完成下 OKR,正好最近幫群友查了一個特殊的 No space left on device 問題,記錄一下。
問題#
半夜接到群友求助,說自己的測試環境遇到了一點問題,正好我還沒睡,那就來看一下
問題的情況很簡單,
用
docker run -d --env-file .oss_env --mount type=bind,src=/data1,dst=/cache {image}啟動了一個容器,然後發現在啟動後業務代碼報錯,拋出 OSError: [Errno 28] No space left on device 的異常
這個問題其實很典型,但是最終排查出來的結果確實非典型的。不過排查思路其實應該是很典型的線上問題的一步步分析 root cause 的過程。希望能對看官就幫助
排查#
首先群友提供了第一個關鍵信息,空間有餘量,但是就 OSError: [Errno 28] No space left on device 。那麼熟悉 Linux 的同學可能第一步的排查工作就是排查對應的 inode 情況
執行命令
df -ih
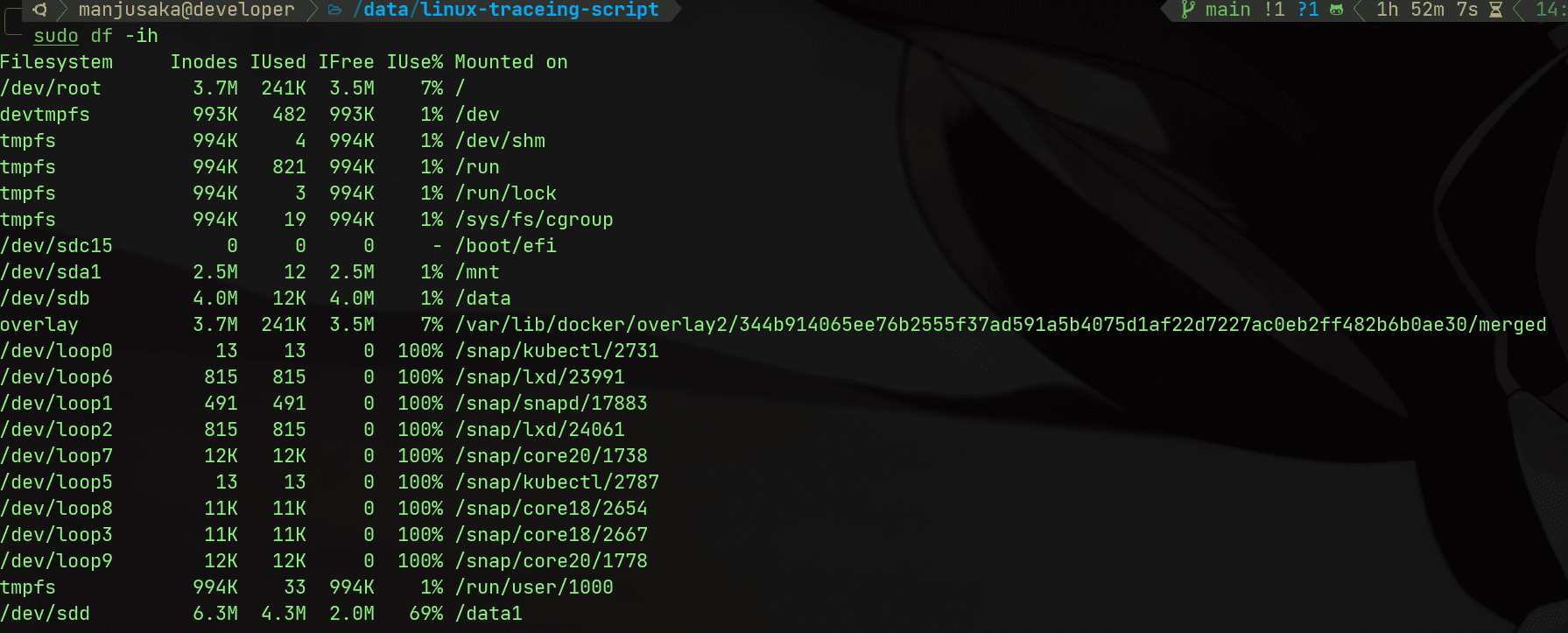
我們能看到 /data1 實際上的 inode 和整機的 inode 數量都是足夠的(備註:這裡是我自己在我自己的機器上復現問題的截圖,第一步由群友完成,然後給我提供了信息)
那麼我們繼續排查,我們看到了我們使用了 mount bind1 的方式將宿主機的 /data1 掛載到了容器內部的 /cache 目錄下,mount bind 可以用下面一張圖來表示和 volume 的區別

都在不同版本的內核上,mount bind 的行為有一些特殊的情況,所以我們需要確認下 mount bind 的情況是否正確,我們用 fallocate2 來創建一個 1G 的文件,然後在容器內部查看文件的大小
fallocate -l 10G /cache/test
文件創建沒有問題,實際上我們就可以排除掉 mount bind 的缺陷了
接著,群友提供了這個盤是雲廠商的雲盤(經過擴容),我讓群友確認下是具體的 ESSD 還是 NAS 這種走 NFS 掛載的 Block Device(這塊也有坑)。確認是標準的 ESSD 後進入下一步(驅動的問題可以先排除)
接著,我們需要考慮 mount --bind 在跨文件系統情況下的問題。雖然前面一步我們成功創建了文件。但是為了保險起見,我們執行 fdisk -l 和 tune2fs -l 兩個命令,來確認分區和文件系統的正確性,確認文件系統的類型都是 ext4,那麼沒有問題。具體兩個命令的使用方式參見 fdisk3 和 tune2fs4
然後再回顧我們之前直接在 /cache 下創建問題沒有問題,那麼這個時候我們心裡應該大概有底,這個應該不是代碼問題,也不是權限問題(這一步我額外排除鏡像的構建里沒有額外的用戶操作),那麼我們需要排除一下擴容的問題。我們將 /data1 unmount 之後,重新 mount 後,再執行容器,發現問題依舊存在,那麼我們就可以去排除擴容的問題了。
現在一些常見的問題已經基本排除,那麼我們來考慮文件系統本身的問題。我登錄到機器上,執行了以下兩個操作
- 在出問題的目錄
/cache/xxx/下,我用fallocate -l創建一個報錯的文件(長文件名),失敗 - 在出問題的目錄
/cache/xxx/下,我用fallocate -l創建一個短文件名),成功
OK,我們現在排查路徑就往文件系統異常的方向上靠了,執行命令 dmesg5 查看內核日誌,發現了如下錯誤
[13155344.231942] EXT4-fs warning (device sdd): ext4_dx_add_entry:2461: Directory (ino: 3145729) index full, reach max htree level :2
[13155344.231944] EXT4-fs warning (device sdd): ext4_dx_add_entry:2465: Large directory feature is not enabled on this filesystem
OK,我們期待的異常信息找到了。原因是,ext4 基於的 BTree 索引,默認情況下只允許樹的層高為 2,實際上就大概限制了目錄下的文件數量大概在 2k-3kw 以內。經過確認,這個問題目錄下的確有大量小文件。我們再用 tune2fs -l 確認下是否是如我們猜想,得到結果
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum
Filesystem flags: signed_directory_hash
bingo,的確沒有開啟 large_dir 的選項。那麼我們執行 tune2fs -O large_dir /dev/sdd 開啟這個選項,然後再次執行 tune2fs -l 確認下,發現已經開啟了。然後我們再次執行容器,發現問題已經解決。
驗證#
上面的問題排查看似告一段落。但是實際上並沒有閉環。一個問題的閉環有兩個特徵
- 定位到具體的異常代碼
- 有最小可復現版本確認我們找到 root cause 是符合預期的。
從上面 dmesg 的信息我們能定位到內核中的函數,其實現如下
static int ext4_dx_add_entry(handle_t *handle, struct ext4_filename *fname,
struct inode *dir, struct inode *inode)
{
struct dx_frame frames[EXT4_HTREE_LEVEL], *frame;
struct dx_entry *entries, *at;
struct buffer_head *bh;
struct super_block *sb = dir->i_sb;
struct ext4_dir_entry_2 *de;
int restart;
int err;
again:
restart = 0;
frame = dx_probe(fname, dir, NULL, frames);
if (IS_ERR(frame))
return PTR_ERR(frame);
entries = frame->entries;
at = frame->at;
bh = ext4_read_dirblock(dir, dx_get_block(frame->at), DIRENT_HTREE);
if (IS_ERR(bh)) {
err = PTR_ERR(bh);
bh = NULL;
goto cleanup;
}
BUFFER_TRACE(bh, "get_write_access");
err = ext4_journal_get_write_access(handle, sb, bh, EXT4_JTR_NONE);
if (err)
goto journal_error;
err = add_dirent_to_buf(handle, fname, dir, inode, NULL, bh);
if (err != -ENOSPC)
goto cleanup;
err = 0;
/* Block full, should compress but for now just split */
dxtrace(printk(KERN_DEBUG "using %u of %u node entries\n",
dx_get_count(entries), dx_get_limit(entries)));
/* Need to split index? */
if (dx_get_count(entries) == dx_get_limit(entries)) {
ext4_lblk_t newblock;
int levels = frame - frames + 1;
unsigned int icount;
int add_level = 1;
struct dx_entry *entries2;
struct dx_node *node2;
struct buffer_head *bh2;
while (frame > frames) {
if (dx_get_count((frame - 1)->entries) <
dx_get_limit((frame - 1)->entries)) {
add_level = 0;
break;
}
frame--; /* split higher index block */
at = frame->at;
entries = frame->entries;
restart = 1;
}
if (add_level && levels == ext4_dir_htree_level(sb)) {
ext4_warning(sb, "Directory (ino: %lu) index full, "
"reach max htree level :%d",
dir->i_ino, levels);
if (ext4_dir_htree_level(sb) < EXT4_HTREE_LEVEL) {
ext4_warning(sb, "Large directory feature is "
"not enabled on this "
"filesystem");
}
err = -ENOSPC;
goto cleanup;
}
icount = dx_get_count(entries);
bh2 = ext4_append(handle, dir, &newblock);
if (IS_ERR(bh2)) {
err = PTR_ERR(bh2);
goto cleanup;
}
node2 = (struct dx_node *)(bh2->b_data);
entries2 = node2->entries;
memset(&node2->fake, 0, sizeof(struct fake_dirent));
node2->fake.rec_len = ext4_rec_len_to_disk(sb->s_blocksize,
sb->s_blocksize);
BUFFER_TRACE(frame->bh, "get_write_access");
err = ext4_journal_get_write_access(handle, sb, frame->bh,
EXT4_JTR_NONE);
if (err)
goto journal_error;
if (!add_level) {
unsigned icount1 = icount/2, icount2 = icount - icount1;
unsigned hash2 = dx_get_hash(entries + icount1);
dxtrace(printk(KERN_DEBUG "Split index %i/%i\n",
icount1, icount2));
BUFFER_TRACE(frame->bh, "get_write_access"); /* index root */
err = ext4_journal_get_write_access(handle, sb,
(frame - 1)->bh,
EXT4_JTR_NONE);
if (err)
goto journal_error;
memcpy((char *) entries2, (char *) (entries + icount1),
icount2 * sizeof(struct dx_entry));
dx_set_count(entries, icount1);
dx_set_count(entries2, icount2);
dx_set_limit(entries2, dx_node_limit(dir));
/* Which index block gets the new entry? */
if (at - entries >= icount1) {
frame->at = at - entries - icount1 + entries2;
frame->entries = entries = entries2;
swap(frame->bh, bh2);
}
dx_insert_block((frame - 1), hash2, newblock);
dxtrace(dx_show_index("node", frame->entries));
dxtrace(dx_show_index("node",
((struct dx_node *) bh2->b_data)->entries));
err = ext4_handle_dirty_dx_node(handle, dir, bh2);
if (err)
goto journal_error;
brelse (bh2);
err = ext4_handle_dirty_dx_node(handle, dir,
(frame - 1)->bh);
if (err)
goto journal_error;
err = ext4_handle_dirty_dx_node(handle, dir,
frame->bh);
if (restart || err)
goto journal_error;
} else {
struct dx_root *dxroot;
memcpy((char *) entries2, (char *) entries,
icount * sizeof(struct dx_entry));
dx_set_limit(entries2, dx_node_limit(dir));
/* Set up root */
dx_set_count(entries, 1);
dx_set_block(entries + 0, newblock);
dxroot = (struct dx_root *)frames[0].bh->b_data;
dxroot->info.indirect_levels += 1;
dxtrace(printk(KERN_DEBUG
"Creating %d level index...\n",
dxroot->info.indirect_levels));
err = ext4_handle_dirty_dx_node(handle, dir, frame->bh);
if (err)
goto journal_error;
err = ext4_handle_dirty_dx_node(handle, dir, bh2);
brelse(bh2);
restart = 1;
goto journal_error;
}
}
de = do_split(handle, dir, &bh, frame, &fname->hinfo);
if (IS_ERR(de)) {
err = PTR_ERR(de);
goto cleanup;
}
err = add_dirent_to_buf(handle, fname, dir, inode, de, bh);
goto cleanup;
journal_error:
ext4_std_error(dir->i_sb, err); /* this is a no-op if err == 0 */
cleanup:
brelse(bh);
dx_release(frames);
/* @restart is true means htree-path has been changed, we need to
* repeat dx_probe() to find out valid htree-path
*/
if (restart && err == 0)
goto again;
return err;
}
ext4_dx_add_entry 函數的主要功能是將新的目錄項添加到目錄索引中,我們能看到這段函數在 add_level && levels == ext4_dir_htree_level(sb) 這裡檢查對應的特性是否打開,以及目前 BTree 層高,如果超出限制,則返回 ENOSPC 即 ERROR 28
好了,在復現異常之前,我們來獲取下這個函數的被調用路徑。這裡我用 eBPF 的 trace 來獲取 stacktrace,因為與主體無關,我在這裡就不放代碼了
ext4_dx_add_entry
ext4_add_nondir
ext4_create
path_openat
do_filp_open
do_sys_openat2
do_sys_open
__x64_sys_openat
do_syscall_64
entry_SYSCALL_64_after_hwframe
[unknown]
[unknown]
那麼我們怎麼驗證這個是我們的異常呢
首先我們利用 eBPF + kretproble 來獲取 ext4_dx_add_entry 的返回值,如果返回值是 ENOSPC,則我們就可以確定這個是我們的異常
代碼如下(不要問我這裡為啥不用 Python 寫,要寫 C 了(
from bcc import BPF
bpf_text = """
#include <uapi/linux/ptrace.h>
BPF_RINGBUF_OUTPUT(events, 65536);
struct event_data_t {
u32 pid;
};
int trace_ext4_dx_add_entry_return(struct pt_regs *ctx) {
int ret = PT_REGS_RC(ctx);
if (ret == 0) {
return 0;
}
u32 pid=bpf_get_current_pid_tgid()>>32;
struct event_data_t *event_data = events.ringbuf_reserve(sizeof(struct event_data_t));
if (!event_data) {
return 0;
}
event_data->pid = pid;
events.ringbuf_submit(event_data, sizeof(event_data));
return 0;
}
"""
bpf = BPF(text=bpf_text)
bpf.attach_kretprobe(event="ext4_dx_add_entry", fn_name="trace_ext4_dx_add_entry_return")
def process_event_data(cpu, data, size):
event = bpf["events"].event(data)
print(f"Process {event.pid} ext4 failed")
bpf["events"].open_ring_buffer(process_event_data)
while True:
try:
bpf.ring_buffer_consume()
except KeyboardInterrupt:
exit()
然後我們寫段很短的 Python 腳本
import uuid
import os
for i in range(200000000):
if i % 100000 == 0:
print(f"we have created {i} files")
filename=str(uuid.uuid4())
file_name=f"/data1/cache/{filename}+{filename}.txt"
with open(file_name, "w+") as f:
f.write("")
然後我們看到執行結果

符合預期,那麼我們可以說這個問題的排查路徑的因果關係鏈完整了。那麼我們也可以正式宣告解決了這個問題了
那麼錦上添花的一點,對於這種上游的問題,我們如果能找到具體在什麼時間點進行了修復,那就更好了。就這個 case 而言,ext4 的 large_dir 在 Linux 4.13 中得到引入,具體可以參見 88a399955a97fe58ddb2a46ca5d988caedac731b6 這個 commit。
OK 這個問題就告一段落
總結#
其實這個問題比較冷門,但是排查方式其實是挺典型的線上問題的排查方法。對於問題,不要預設結果,一步步的根據現象去逼近最終的結論。以及 eBPF 真的好東西,能幫助做很多內核的事。最後我的 Linux 文件系統方面的底子還是太薄弱了,希望後面能重點加強一下
差不多就這樣