久しぶりに水文を書きました。新年最初の水文は書かないといけませんね。OKR を達成するために、最近、友人のために特殊な「デバイスに空きスペースがありません」という問題を調査したので、記録しておきます。
問題#
真夜中に友人から助けを求められました。彼のテスト環境に問題が発生したとのこと。ちょうど私はまだ起きていたので、見てみることにしました。
問題の状況は非常にシンプルです。
docker run -d --env-file .oss_env --mount type=bind,src=/data1,dst=/cache {image}でコンテナを起動したところ、起動後に業務コードがエラーを報告し、OSError: [Errno 28] デバイスに空きスペースがありませんという例外が発生しました。
この問題は実際には非常に典型的ですが、最終的に調査した結果は確かに非典型的でした。しかし、調査の考え方は、実際の問題の根本原因を一歩一歩分析する典型的なオンライン問題のプロセスであるべきです。見ている方にとって助けになることを願っています。
排查#
まず、友人が最初の重要な情報を提供してくれました。空き容量はあるのに、OSError: [Errno 28] デバイスに空きスペースがありませんということです。Linux に詳しい方は、最初の調査作業として対応する inode の状況を確認するかもしれません。
コマンドを実行します。
df -ih
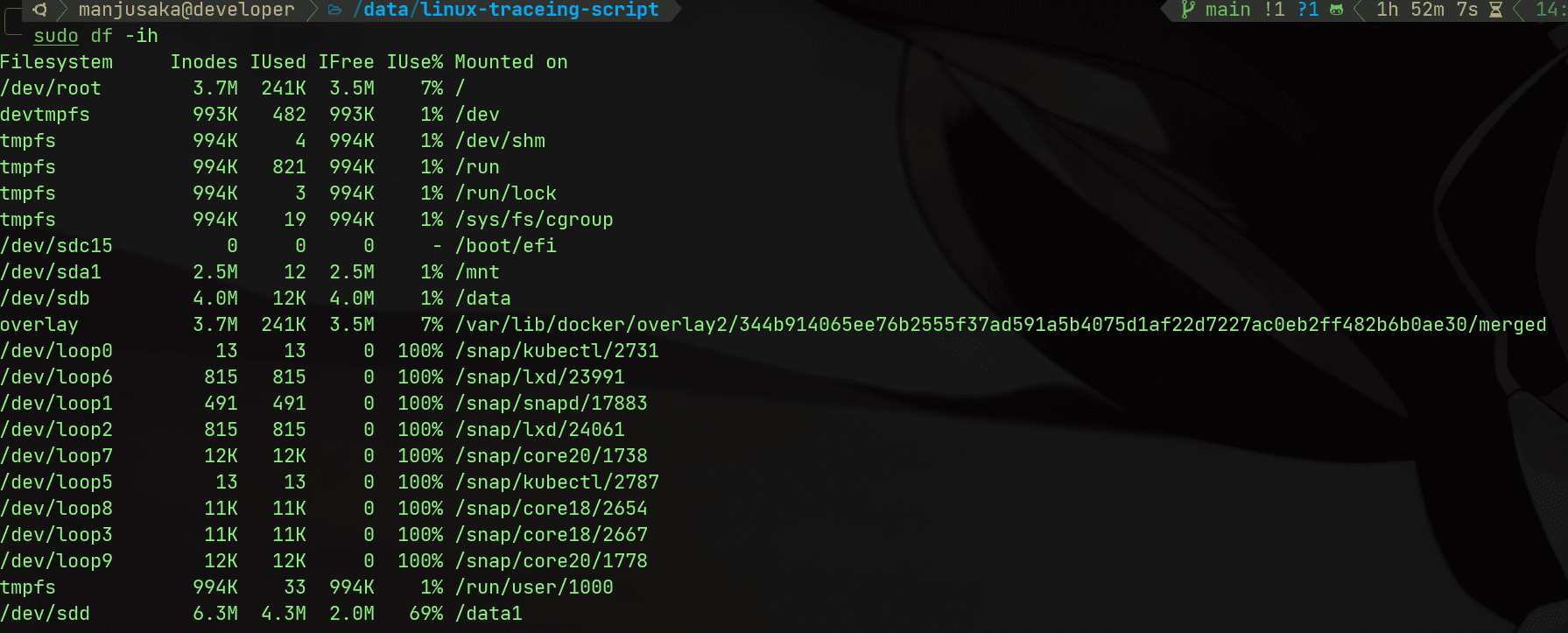
私たちは、/data1 の実際の inode と全体の inode の数が十分であることがわかります(注:ここは私が自分のマシンで問題を再現したスクリーンショットで、最初のステップは友人が完了し、その後私に情報を提供してくれました)。
それでは、さらに調査を続けましょう。私たちは、ホストの /data1 をコンテナ内部の /cache ディレクトリにマウントするためにmount bind1の方法を使用したことがわかりました。mount bind は、以下の図でボリュームとの違いを示すことができます。

異なるバージョンのカーネル上で、mount bind の動作にはいくつか特別な状況がありますので、mount bind の状況が正しいかどうかを確認する必要があります。私たちはfallocate2を使用して 1G のファイルを作成し、コンテナ内部でファイルのサイズを確認します。
fallocate -l 10G /cache/test
ファイルの作成には問題がなく、実際には mount bind の欠陥を排除できました。
次に、友人がこのディスクはクラウドプロバイダーのクラウドディスク(拡張済み)であることを提供してくれました。私は友人に具体的な ESSD か、NFS マウントを使用する NAS のようなブロックデバイスかを確認させました(この部分にも落とし穴があります)。標準の ESSD であることが確認された後、次のステップに進みます(ドライバの問題は一旦排除できます)。
次に、私たちは mount --bind がファイルシステムを跨いでいる場合の問題を考慮する必要があります。前のステップでファイルを正常に作成しましたが、念のため、fdisk -lとtune2fs -lの 2 つのコマンドを実行して、パーティションとファイルシステムの正確性を確認し、ファイルシステムのタイプがすべて ext4 であることを確認しましたので、問題ありません。具体的な 2 つのコマンドの使用方法については、fdisk3とtune2fs4を参照してください。
それから、私たちは以前に /cache の下で直接作成した問題がなかったことを振り返りますので、この時点で私たちはおそらくこの問題がコードの問題ではなく、権限の問題でもないことを理解するべきです(このステップでは、イメージの構築に追加のユーザー操作がないことを排除しました)。それでは、拡張の問題を排除する必要があります。/data1 をアンマウントした後、再度マウントし、コンテナを実行すると、問題は依然として存在しましたので、拡張の問題を排除できます。
現在、いくつかの一般的な問題は基本的に排除されましたので、ファイルシステム自体の問題を考慮しましょう。私はマシンにログインし、以下の 2 つの操作を実行しました。
- 問題のディレクトリ
/cache/xxx/で、fallocate -lを使用してエラーのあるファイル(長いファイル名)を作成し、失敗しました。 - 問題のディレクトリ
/cache/xxx/で、fallocate -lを使用して短いファイル名を作成し、成功しました。
さて、私たちは現在、ファイルシステムの異常の方向に調査を進めています。コマンドdmesg5を実行してカーネルログを確認すると、以下のエラーが見つかりました。
[13155344.231942] EXT4-fs warning (device sdd): ext4_dx_add_entry:2461: Directory (ino: 3145729) index full, reach max htree level :2
[13155344.231944] EXT4-fs warning (device sdd): ext4_dx_add_entry:2465: Large directory feature is not enabled on this filesystem
OK、期待していた異常情報が見つかりました。原因は、ext4 が基づく BTree インデックスが、デフォルトでは木の高さを 2 に制限しているため、実際にはディレクトリ内のファイル数が約 2k-3kw 以内に制限されます。確認したところ、この問題のディレクトリには大量の小さなファイルが存在しました。私たちは再度tune2fs -lを使用して、私たちの推測が正しいかどうかを確認し、結果を得ました。
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum
Filesystem flags: signed_directory_hash
ビンゴ、確かにlarge_dirオプションは有効になっていませんでした。それでは、tune2fs -O large_dir /dev/sddを実行してこのオプションを有効にし、再度tune2fs -lを実行して確認すると、すでに有効になっていました。そして、再度コンテナを実行すると、問題が解決されていることがわかりました。
検証#
上記の問題の調査は一段落したように見えますが、実際には閉じていません。問題の閉じるには 2 つの特徴があります。
- 具体的な異常コードを特定すること
- 最小限の再現バージョンを確認し、私たちが見つけた根本原因が期待通りであることを確認すること。
上記の dmesg の情報から、私たちはカーネル内の関数を特定できます。その実装は以下の通りです。
static int ext4_dx_add_entry(handle_t *handle, struct ext4_filename *fname,
struct inode *dir, struct inode *inode)
{
struct dx_frame frames[EXT4_HTREE_LEVEL], *frame;
struct dx_entry *entries, *at;
struct buffer_head *bh;
struct super_block *sb = dir->i_sb;
struct ext4_dir_entry_2 *de;
int restart;
int err;
again:
restart = 0;
frame = dx_probe(fname, dir, NULL, frames);
if (IS_ERR(frame))
return PTR_ERR(frame);
entries = frame->entries;
at = frame->at;
bh = ext4_read_dirblock(dir, dx_get_block(frame->at), DIRENT_HTREE);
if (IS_ERR(bh)) {
err = PTR_ERR(bh);
bh = NULL;
goto cleanup;
}
BUFFER_TRACE(bh, "get_write_access");
err = ext4_journal_get_write_access(handle, sb, bh, EXT4_JTR_NONE);
if (err)
goto journal_error;
err = add_dirent_to_buf(handle, fname, dir, inode, NULL, bh);
if (err != -ENOSPC)
goto cleanup;
err = 0;
/* Block full, should compress but for now just split */
dxtrace(printk(KERN_DEBUG "using %u of %u node entries\n",
dx_get_count(entries), dx_get_limit(entries)));
/* Need to split index? */
if (dx_get_count(entries) == dx_get_limit(entries)) {
ext4_lblk_t newblock;
int levels = frame - frames + 1;
unsigned int icount;
int add_level = 1;
struct dx_entry *entries2;
struct dx_node *node2;
struct buffer_head *bh2;
while (frame > frames) {
if (dx_get_count((frame - 1)->entries) <
dx_get_limit((frame - 1)->entries)) {
add_level = 0;
break;
}
frame--; /* split higher index block */
at = frame->at;
entries = frame->entries;
restart = 1;
}
if (add_level && levels == ext4_dir_htree_level(sb)) {
ext4_warning(sb, "Directory (ino: %lu) index full, "
"reach max htree level :%d",
dir->i_ino, levels);
if (ext4_dir_htree_level(sb) < EXT4_HTREE_LEVEL) {
ext4_warning(sb, "Large directory feature is "
"not enabled on this "
"filesystem");
}
err = -ENOSPC;
goto cleanup;
}
icount = dx_get_count(entries);
bh2 = ext4_append(handle, dir, &newblock);
if (IS_ERR(bh2)) {
err = PTR_ERR(bh2);
goto cleanup;
}
node2 = (struct dx_node *)(bh2->b_data);
entries2 = node2->entries;
memset(&node2->fake, 0, sizeof(struct fake_dirent));
node2->fake.rec_len = ext4_rec_len_to_disk(sb->s_blocksize,
sb->s_blocksize);
BUFFER_TRACE(frame->bh, "get_write_access");
err = ext4_journal_get_write_access(handle, sb, frame->bh,
EXT4_JTR_NONE);
if (err)
goto journal_error;
if (!add_level) {
unsigned icount1 = icount/2, icount2 = icount - icount1;
unsigned hash2 = dx_get_hash(entries + icount1);
dxtrace(printk(KERN_DEBUG "Split index %i/%i\n",
icount1, icount2));
BUFFER_TRACE(frame->bh, "get_write_access"); /* index root */
err = ext4_journal_get_write_access(handle, sb,
(frame - 1)->bh,
EXT4_JTR_NONE);
if (err)
goto journal_error;
memcpy((char *) entries2, (char *) (entries + icount1),
icount2 * sizeof(struct dx_entry));
dx_set_count(entries, icount1);
dx_set_count(entries2, icount2);
dx_set_limit(entries2, dx_node_limit(dir));
/* Which index block gets the new entry? */
if (at - entries >= icount1) {
frame->at = at - entries - icount1 + entries2;
frame->entries = entries = entries2;
swap(frame->bh, bh2);
}
dx_insert_block((frame - 1), hash2, newblock);
dxtrace(dx_show_index("node", frame->entries));
dxtrace(dx_show_index("node",
((struct dx_node *) bh2->b_data)->entries));
err = ext4_handle_dirty_dx_node(handle, dir, bh2);
if (err)
goto journal_error;
brelse (bh2);
err = ext4_handle_dirty_dx_node(handle, dir,
(frame - 1)->bh);
if (err)
goto journal_error;
err = ext4_handle_dirty_dx_node(handle, dir,
frame->bh);
if (restart || err)
goto journal_error;
} else {
struct dx_root *dxroot;
memcpy((char *) entries2, (char *) entries,
icount * sizeof(struct dx_entry));
dx_set_limit(entries2, dx_node_limit(dir));
/* Set up root */
dx_set_count(entries, 1);
dx_set_block(entries + 0, newblock);
dxroot = (struct dx_root *)frames[0].bh->b_data;
dxroot->info.indirect_levels += 1;
dxtrace(printk(KERN_DEBUG
"Creating %d level index...\n",
dxroot->info.indirect_levels));
err = ext4_handle_dirty_dx_node(handle, dir, frame->bh);
if (err)
goto journal_error;
err = ext4_handle_dirty_dx_node(handle, dir, bh2);
brelse(bh2);
restart = 1;
goto journal_error;
}
}
de = do_split(handle, dir, &bh, frame, &fname->hinfo);
if (IS_ERR(de)) {
err = PTR_ERR(de);
goto cleanup;
}
err = add_dirent_to_buf(handle, fname, dir, inode, de, bh);
goto cleanup;
journal_error:
ext4_std_error(dir->i_sb, err); /* this is a no-op if err == 0 */
cleanup:
brelse(bh);
dx_release(frames);
/* @restart is true means htree-path has been changed, we need to
* repeat dx_probe() to find out valid htree-path
*/
if (restart && err == 0)
goto again;
return err;
}
ext4_dx_add_entry関数の主な機能は、新しいディレクトリエントリをディレクトリインデックスに追加することです。この関数がadd_level && levels == ext4_dir_htree_level(sb)で対応する機能が有効になっているかどうかを確認し、現在の BTree の高さを確認し、制限を超えた場合はENOSPC、つまり ERROR 28 を返します。
さて、異常を再現する前に、この関数の呼び出しパスを取得しましょう。ここでは、eBPF のトレースを使用してスタックトレースを取得しますので、主体とは関係ないため、ここではコードを掲載しません。
ext4_dx_add_entry
ext4_add_nondir
ext4_create
path_openat
do_filp_open
do_sys_openat2
do_sys_open
__x64_sys_openat
do_syscall_64
entry_SYSCALL_64_after_hwframe
[unknown]
[unknown]
それでは、どのようにしてこれが私たちの異常であることを確認するのでしょうか。
まず、eBPF + kretprobe を利用してext4_dx_add_entryの戻り値を取得します。戻り値がENOSPCであれば、これが私たちの異常であることが確定します。
コードは以下の通りです(なぜここで Python を使わずに C を書くのかは聞かないでください)。
from bcc import BPF
bpf_text = """
#include <uapi/linux/ptrace.h>
BPF_RINGBUF_OUTPUT(events, 65536);
struct event_data_t {
u32 pid;
};
int trace_ext4_dx_add_entry_return(struct pt_regs *ctx) {
int ret = PT_REGS_RC(ctx);
if (ret == 0) {
return 0;
}
u32 pid=bpf_get_current_pid_tgid()>>32;
struct event_data_t *event_data = events.ringbuf_reserve(sizeof(struct event_data_t));
if (!event_data) {
return 0;
}
event_data->pid = pid;
events.ringbuf_submit(event_data, sizeof(event_data));
return 0;
}
"""
bpf = BPF(text=bpf_text)
bpf.attach_kretprobe(event="ext4_dx_add_entry", fn_name="trace_ext4_dx_add_entry_return")
def process_event_data(cpu, data, size):
event = bpf["events"].event(data)
print(f"Process {event.pid} ext4 failed")
bpf["events"].open_ring_buffer(process_event_data)
while True:
try:
bpf.ring_buffer_consume()
except KeyboardInterrupt:
exit()
次に、非常に短い Python スクリプトを書きます。
import uuid
import os
for i in range(200000000):
if i % 100000 == 0:
print(f"we have created {i} files")
filename=str(uuid.uuid4())
file_name=f"/data1/cache/{filename}+{filename}.txt"
with open(file_name, "w+") as f:
f.write("")
そして、実行結果を確認します。

期待通りの結果が得られましたので、この問題の調査パスの因果関係が完全であると言えます。これでこの問題が解決されたと正式に宣言できます。
さて、さらに良い点として、このような上流の問題について、具体的にどの時点で修正が行われたかを見つけることができれば、さらに良いでしょう。このケースに関して言えば、ext4 の large_dir は Linux 4.13 で導入されました。具体的には、88a399955a97fe58ddb2a46ca5d988caedac731b6というコミットを参照してください。
さて、この問題は一段落しました。
まとめ#
実際、この問題はあまり一般的ではありませんが、調査方法は典型的なオンライン問題の調査方法です。問題に対して、結果を予測せず、現象に基づいて最終的な結論に近づくことが重要です。また、eBPF は本当に素晴らしいもので、多くのカーネル関連の作業を助けてくれます。最後に、私の Linux ファイルシステムに関する基礎知識はまだまだ薄いので、今後は重点的に強化していきたいと思います。
だいたいこんな感じです。