新年了,決定趁著有時間的時候多寫幾篇技術水文。今天的話,準備來簡單聊聊容器中我們每天都會接觸,但是時常又會被我們忽略的一號進程
正文#
容器技術發展到現在,其實形態上已經發生了很大的變化。根據不同的場景,既有傳統的 Docker1, containterd2 這樣傳統基於 CGroup + Namespace 的容器形態,也有像 Kata3 這樣基於 VM 的新型的容器形態。本文主要著眼在傳統容器中一號進程上。
我們都知道,傳統容器依賴的 CGroup + Namespace 進行資源隔離,本質上來說,還是 OS 內的一個進程。所以在繼續往下聊容器相關的內容之前,我們需要先來簡單聊聊 Linux 中的進程管理
Linux 中的進程管理#
簡單聊聊進程#
Linux 中的進程實際上是個非常大的話題,如果要展開聊,實際上這個話題可以聊一整本書 = =,所以為了時間著想,我們還是把目光聚集在最核心的一部分上面(實際上是因為很多東西我也不懂)。
首先來講,在內核中利用一個特殊的結構體來維護進程有關的相關信息,比如常見的 PID,進程狀態,打開的文件描述符等信息。在內核代碼中,這個結構體是 task_struct4, 其大概結構大家可以看一下下圖
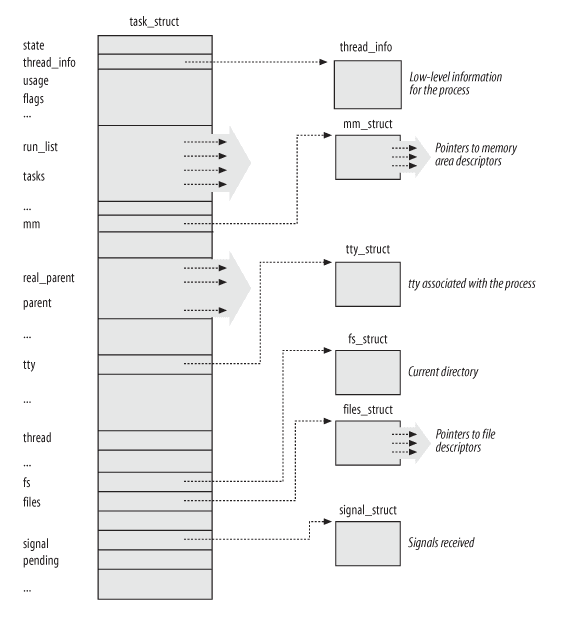
而通常而言,我們會在系統上跑很多個進程。所以內核用一個進程表 (實際上 Linux 中管理進程表的有多個數據結構,這裡我們用 PID Hash Map 來舉例)來維護所有 Process Descriptor 相關的信息,詳見下圖

OK,這裡我們大概了解了進程中的基本結構,現在我們來看我們常見使用進程的一個場景:父子進程。我們都知道,我們有時會在一個進程中,通過 fork5 這個 sys call 來創建出一個新的進程。通常來說,我們創建的新的進程是當前進程的子進程。那么在內核中怎麼表達這種父子關係呢?
回到剛剛提到 task_struct, 在這個結構體中存在這樣幾個字段來描述父子關係
-
real_parent:一個 task_struct 指針,指向父進程
-
parent: 一個 task_struct 指針,指向父進程。在大多數情況下,這個字段的值和
real_parent一致。在有進程對當前進程使用 ptrace6 等情況的時候,和real_parent字段不一致 -
children:list_head, 其指向一個由當前進程所創建的所有子進程的雙向鏈表
這裡大家可能還有點抽象的話,給大家一個圖就能看清楚了
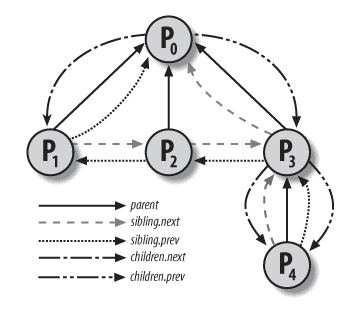
實際上,我們發現,不同進程之間的父子關係,反應到具體的數據結構之上,就形成了一個完整的樹形結構(先記住這點,我們稍後會再提到這裡)
到現在為止,我們已經對 Linux 中的進程,有了最簡單一個概念,那麼接下來,我們會聊聊我們在進程使用中常遇到的兩個問題:孤兒進程 && 殭屍進程
孤兒進程 && 殭屍進程#
首先來聊聊 殭屍進程 這個概念。
如前面所說,我們內核有進程表來維護 Process Descriptor 相關信息。那么在 Linux 的設計中,當一個子進程退出後,將保存自己的進程相關的狀態以供父進程使用。而父進程將調用 waitpid7 來獲取子進程狀態,並清理相關資源。
那麼如上所說,父進程是有可能需要拿到子進程相關的狀態的。那么也就導致為了滿足這一設計,內核中的進程表將一直保存相關資源。當殭屍進程多了以後,那麼將造成很大的資源浪費。
首先來看一個簡單的殭屍進程的例子
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int pid;
if ((pid = fork()) == 0) {
printf("Here's child process\n");
} else {
printf("the child process pid is %d\n", pid);
sleep(20);
}
return 0;
}
然後我們編譯執行這段代碼,然後配合 ps 命令查看一下,發現我們的確造了一個 z 進程
![]()
OK 我們再來看一個正確處理子進程退出的代碼
#include <errno.h>
#include <signal.h>
#include <stdio.h>
#include <string.h>
#include <sys/epoll.h>
#include <sys/signalfd.h>
#include <sys/wait.h>
#define MAXEVENTS 64
void deletejob(pid_t pid) { printf("delete task %d\n", pid); }
void addjob(pid_t pid) { printf("add task %d\n", pid); }
int main(int argc, char **argv) {
int pid;
struct epoll_event event;
struct epoll_event *events;
sigset_t mask;
sigemptyset(&mask);
sigaddset(&mask, SIGCHLD);
if (sigprocmask(SIG_SETMASK, &mask, NULL) < 0) {
perror("sigprocmask");
return 1;
}
int sfd = signalfd(-1, &mask, 0);
int epoll_fd = epoll_create(MAXEVENTS);
event.events = EPOLLIN | EPOLLEXCLUSIVE | EPOLLET;
event.data.fd = sfd;
int s = epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sfd, &event);
if (s == -1) {
abort();
}
events = calloc(MAXEVENTS, sizeof(event));
while (1) {
int n = epoll_wait(epoll_fd, events, MAXEVENTS, 1);
if (n == -1) {
if (errno == EINTR) {
fprintf(stderr, "epoll EINTR error\n");
} else if (errno == EINVAL) {
fprintf(stderr, "epoll EINVAL error\n");
} else if (errno == EFAULT) {
fprintf(stderr, "epoll EFAULT error\n");
exit(-1);
} else if (errno == EBADF) {
fprintf(stderr, "epoll EBADF error\n");
exit(-1);
}
}
printf("%d\n", n);
for (int i = 0; i < n; i++) {
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN))) {
printf("%d\n", i);
fprintf(stderr, "epoll err\n");
close(events[i].data.fd);
continue;
} else if (sfd == events[i].data.fd) {
struct signalfd_siginfo si;
ssize_t res = read(sfd, &si, sizeof(si));
if (res < 0) {
fprintf(stderr, "read error\n");
continue;
}
if (res != sizeof(si)) {
fprintf(stderr, "Something wrong\n");
continue;
}
if (si.ssi_signo == SIGCHLD) {
printf("Got SIGCHLD\n");
int child_pid = waitpid(-1, NULL, 0);
deletejob(child_pid);
}
}
}
if ((pid = fork()) == 0) {
execve("/bin/date", argv, NULL);
}
addjob(pid);
}
}
OK, 我們現在都知道了,子進程退出後需要由父進程正確的回收相關的資源。那么問題來了,我們父進程先於子進程退出了怎麼辦。實際上這是一個很常見的場景。比如說大家去用兩次 fork 實現守護進程。
我們常規的認知來說,我們父進程退出後,這個進程所屬的所有子進程會進行 re-parent 到當前 PID Namespace 的一號進程上,那麼這樣的答案是正確的麼?對,也不對,我們首先來看一個例子
#include <stdio.h>
#include <sys/prctl.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int pid;
int err = prctl(PR_SET_CHILD_SUBREAPER, 1);
if (err != 0) {
return 0;
}
if ((pid = fork()) == 0) {
if ((pid = fork()) == 0) {
printf("Here's child process1\n");
sleep(20);
} else {
printf("the child process pid is %d\n", pid);
}
} else {
sleep(40);
}
return 0;
}
這是一個很典型的兩次 fork 創建守護進程的代碼(除了我沒寫 SIGCHLD 處理(逃)。我們來看下這段代碼的輸出

我們能看到守護進程的 PID 是 449920
然後我們執行 ps -efj 和 ps auf 兩個命令看一下結果

我們能看到,449920 這個進程在父進程退出後沒有 re-parent 到當前空間的一號進程上。這是為什麼呢?可能眼尖的同學已經注意到這段代碼中一個特殊的 sys call prctl8。我們給當前進程設置了 PR_SET_CHILD_SUBREAPER 的屬性。
這裡我們來看一下內核裡的實現
/*
* When we die, we re-parent all our children, and try to:
* 1. give them to another thread in our thread group, if such a member exists
* 2. give it to the first ancestor process which prctl'd itself as a
* child_subreaper for its children (like a service manager)
* 3. give it to the init process (PID 1) in our pid namespace
*/
static struct task_struct *find_new_reaper(struct task_struct *father,
struct task_struct *child_reaper)
{
struct task_struct *thread, *reaper;
thread = find_alive_thread(father);
if (thread)
return thread;
if (father->signal->has_child_subreaper) {
unsigned int ns_level = task_pid(father)->level;
/*
* Find the first ->is_child_subreaper ancestor in our pid_ns.
* We can't check reaper != child_reaper to ensure we do not
* cross the namespaces, the exiting parent could be injected
* by setns() + fork().
* We check pid->level, this is slightly more efficient than
* task_active_pid_ns(reaper) != task_active_pid_ns(father).
*/
for (reaper = father->real_parent;
task_pid(reaper)->level == ns_level;
reaper = reaper->real_parent) {
if (reaper == &init_task)
break;
if (!reaper->signal->is_child_subreaper)
continue;
thread = find_alive_thread(reaper);
if (thread)
return thread;
}
}
return child_reaper;
}
這裡我們總結一下,當父進程退出後,所屬的子進程,將按照如下順序進行 re-parent
-
線程組裡其餘可用線程(這裡的線程有所不一樣,可以暫時忽略)
-
在當前所屬的進程樹上不斷尋找設置了 PR_SET_CHILD_SUBREAPER 進程
-
在前面兩者都無效的情況下,re-parent 到當前 PID Namespace 中的 1 號進程上
到這裡,我們關於 Linux 中進程管理的基礎介紹就完成了。那麼我們將來聊聊容器中的情況
容器中的一號進程#
這裡,我們將利用,Docker 作為背景聊聊這個話題。首先,在 Docker 1.11 之後,其架構發生了比較大的變化,如下圖所示

那麼我們拉起一個容器的的流程如下
-
Docker Daemon 向 containerd 發送指令
-
containerd 創建一個 containterd-shim 進程
-
containerd-shim 創建一個 runc 進程
-
runc 進程將根據 OCI 標準,設置相關環境(創建 cgroup,創建 ns 等),然後執行
entrypoint中的設定的命令 -
runc 在執行完相關設置後,將自我退出,此時其子進程(即容器命名空間內的一號進程)將被 re-parent 給 containerd-shim 進程。
OK,上面 step 5 操作,就需要依賴我們上節中講到的 prctl 和 PR_SET_CHILD_SUBREAPER 。
自此,containerd-shim 將承擔容器內進程相關的操作,即便其父進程退出,子進程也會根據 re-parent 的流程托管到 containerd-shim 進程上。
那麼,這樣是不是就沒有問題了呢?
答案很明顯不是。來給大家舉一個實際上的場景:假設我一個服務需要實現一個需求叫做優雅下線。通常而言,我們會在暴力殺死進程之前,利用 SIGTERM 信號實現這個功能。但是在容器時期有個問題,我們一號進程,可能不是程序本身(比如大家習慣性的會考慮在 entrypoint 中用 bash 去裹一層),或者經過一些特殊場景,容器中的進程,全部已經托管在 containerd-shim 上了。而 contaninerd-shim 是不具備信號轉發的能力的。
所以在這樣一些場景下,我們就需要考慮額外引入一些組件來完成我們的需求。這裡以一個非常輕量級的專門針對容器的設計的一號進程項目 tini9 來作為介紹
我們這裡看一下核心的一些代碼
int register_subreaper () {
if (subreaper > 0) {
if (prctl(PR_SET_CHILD_SUBREAPER, 1)) {
if (errno == EINVAL) {
PRINT_FATAL("PR_SET_CHILD_SUBREAPER is unavailable on this platform. Are you using Linux >= 3.4?")
} else {
PRINT_FATAL("Failed to register as child subreaper: %s", strerror(errno))
}
return 1;
} else {
PRINT_TRACE("Registered as child subreaper");
}
}
return 0;
}
int wait_and_forward_signal(sigset_t const* const parent_sigset_ptr, pid_t const child_pid) {
siginfo_t sig;
if (sigtimedwait(parent_sigset_ptr, &sig, &ts) == -1) {
switch (errno) {
case EAGAIN:
break;
case EINTR:
break;
default:
PRINT_FATAL("Unexpected error in sigtimedwait: '%s'", strerror(errno));
return 1;
}
} else {
/* There is a signal to handle here */
switch (sig.si_signo) {
case SIGCHLD:
/* Special-cased, as we don't forward SIGCHLD. Instead, we'll
* fallthrough to reaping processes.
*/
PRINT_DEBUG("Received SIGCHLD");
break;
default:
PRINT_DEBUG("Passing signal: '%s'", strsignal(sig.si_signo));
/* Forward anything else */
if (kill(kill_process_group ? -child_pid : child_pid, sig.si_signo)) {
if (errno == ESRCH) {
PRINT_WARNING("Child was dead when forwarding signal");
} else {
PRINT_FATAL("Unexpected error when forwarding signal: '%s'", strerror(errno));
return 1;
}
}
break;
}
}
return 0;
}
這裡我們能很清楚看到兩個核心點
-
tini 會通過 prctl 和 PR_SET_CHILD_SUBREAPER 來接管容器內的孤兒進程
-
tini 在收到信號後,會將信號轉發給子進程或者是所屬的子進程組
當然其實 tini 本身也有一些小問題(不過比較冷門)這裡留一個討論題:假設我們有這樣一個服務,在創建 10 個守護進程後自己退出。在這十個守護進程中,我們都會設置一個全新的進程組 ID (所謂進程組逃逸)。那麼我們怎麼樣將信號轉發到這十個進程上(僅供討論,生產上這麼幹的人早被打死了)
總結#
可能看到這裡,可能有人要噴我不講武德,說好的容器內一號進程,但是花了大半篇幅來講 Linux 進程 233333.
實際上傳統容器基本可以認為是在 OS 中執行的一個完整進程。討論容器中的一號進程離不開討論 Linux 中進程管理的相關知識點。
希望通過這篇技術水文能幫大家對容器中一號進程有個大概的認知,並能正確的使用和管理他。
最後祝大家新年快樂!(希望新年我能不以寫水文為生,呜呜呜呜)
Reference#
- [1]. Docker
- [2]. containerd
- [3]. kata
- [4]. task_struct
- [5]. Linux Man Page: fork
- [9]. tini