The New Year has arrived, and I've decided to take advantage of my free time to write a few more technical articles. Today, I would like to briefly discuss the init process, which we encounter daily in containers but often overlook.
Main Text#
As container technology has developed, its forms have changed significantly. Depending on different scenarios, there are traditional container forms based on CGroup + Namespace like Docker1 and containerd2, as well as new forms based on VMs like Kata3. This article mainly focuses on the init process in traditional containers.
We all know that traditional containers rely on CGroup + Namespace for resource isolation, and essentially, they are still a process within the OS. Therefore, before we continue discussing container-related content, we need to briefly talk about process management in Linux.
Process Management in Linux#
A Brief Discussion on Processes#
Processes in Linux are actually a very broad topic. If we were to elaborate, it could fill an entire book. Therefore, for the sake of time, let's focus on the most core aspects (mainly because there are many things I don't understand either).
First, the kernel uses a special structure to maintain information related to processes, such as the common PID, process state, open file descriptors, and so on. In the kernel code, this structure is called task_struct4. You can see its approximate structure in the image below.
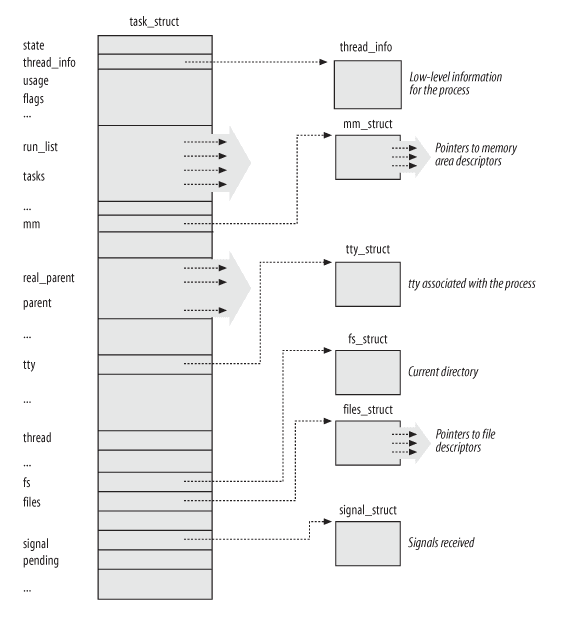
Typically, we run many processes on the system. Therefore, the kernel uses a process table (in fact, there are multiple data structures managing the process table in Linux; here we use the PID Hash Map as an example) to maintain all Process Descriptor-related information, as shown in the image below.

OK, now that we have a basic understanding of the structure of processes, let's look at a common scenario involving processes: parent and child processes. We all know that sometimes we create a new process in a process using the fork5 syscall. Generally, the new process we create is a child process of the current process. So how is this parent-child relationship expressed in the kernel?
Returning to the previously mentioned task_struct, this structure contains several fields to describe the parent-child relationship:
-
real_parent: A task_struct pointer pointing to the parent process.
-
parent: A task_struct pointer pointing to the parent process. In most cases, the value of this field is consistent with
real_parent. However, in cases where a process uses ptrace6 on the current process, it may differ from thereal_parentfield. -
children: list_head, which points to a doubly linked list of all child processes created by the current process.
This might still seem abstract, so here's a diagram to clarify.
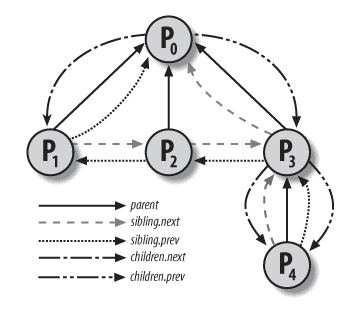
In fact, we find that the parent-child relationships between different processes, reflected in the specific data structure, form a complete tree structure (keep this in mind; we will refer back to it later).
So far, we have a basic concept of processes in Linux. Next, we will discuss two common issues we encounter when using processes: orphan processes and zombie processes.
Orphan Processes & Zombie Processes#
First, let's talk about the concept of a zombie process.
As mentioned earlier, the kernel has a process table to maintain Process Descriptor-related information. In Linux's design, when a child process exits, it retains its process-related state for the parent process to use. The parent process will call waitpid7 to obtain the child process's state and clean up related resources.
As stated, the parent process may need to retrieve the state of the child process. This leads to the kernel's process table retaining related resources. When there are many zombie processes, it can cause significant resource waste.
First, let's look at a simple example of a zombie process.
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int pid;
if ((pid = fork()) == 0) {
printf("Here's child process\n");
} else {
printf("the child process pid is %d\n", pid);
sleep(20);
}
return 0;
}
Then we compile and execute this code, and use the ps command to check, and we find that we indeed created a zombie process.
![]()
OK, now let's look at a correct way to handle the exit of a child process.
#include <errno.h>
#include <signal.h>
#include <stdio.h>
#include <string.h>
#include <sys/epoll.h>
#include <sys/signalfd.h>
#include <sys/wait.h>
#define MAXEVENTS 64
void deletejob(pid_t pid) { printf("delete task %d\n", pid); }
void addjob(pid_t pid) { printf("add task %d\n", pid); }
int main(int argc, char **argv) {
int pid;
struct epoll_event event;
struct epoll_event *events;
sigset_t mask;
sigemptyset(&mask);
sigaddset(&mask, SIGCHLD);
if (sigprocmask(SIG_SETMASK, &mask, NULL) < 0) {
perror("sigprocmask");
return 1;
}
int sfd = signalfd(-1, &mask, 0);
int epoll_fd = epoll_create(MAXEVENTS);
event.events = EPOLLIN | EPOLLEXCLUSIVE | EPOLLET;
event.data.fd = sfd;
int s = epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sfd, &event);
if (s == -1) {
abort();
}
events = calloc(MAXEVENTS, sizeof(event));
while (1) {
int n = epoll_wait(epoll_fd, events, MAXEVENTS, 1);
if (n == -1) {
if (errno == EINTR) {
fprintf(stderr, "epoll EINTR error\n");
} else if (errno == EINVAL) {
fprintf(stderr, "epoll EINVAL error\n");
} else if (errno == EFAULT) {
fprintf(stderr, "epoll EFAULT error\n");
exit(-1);
} else if (errno == EBADF) {
fprintf(stderr, "epoll EBADF error\n");
exit(-1);
}
}
printf("%d\n", n);
for (int i = 0; i < n; i++) {
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN))) {
printf("%d\n", i);
fprintf(stderr, "epoll err\n");
close(events[i].data.fd);
continue;
} else if (sfd == events[i].data.fd) {
struct signalfd_siginfo si;
ssize_t res = read(sfd, &si, sizeof(si));
if (res < 0) {
fprintf(stderr, "read error\n");
continue;
}
if (res != sizeof(si)) {
fprintf(stderr, "Something wrong\n");
continue;
}
if (si.ssi_signo == SIGCHLD) {
printf("Got SIGCHLD\n");
int child_pid = waitpid(-1, NULL, 0);
deletejob(child_pid);
}
}
}
if ((pid = fork()) == 0) {
execve("/bin/date", argv, NULL);
}
addjob(pid);
}
}
OK, now we all know that after a child process exits, the parent process needs to correctly reclaim the related resources. But what happens if the parent process exits before the child process? In fact, this is a very common scenario. For example, when using two forks to implement a daemon process.
In our conventional understanding, when the parent process exits, all child processes belonging to this process will be re-parented to the init process of the current PID Namespace. Is this answer correct? Yes and no. Let's first look at an example.
#include <stdio.h>
#include <sys/prctl.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int pid;
int err = prctl(PR_SET_CHILD_SUBREAPER, 1);
if (err != 0) {
return 0;
}
if ((pid = fork()) == 0) {
if ((pid = fork()) == 0) {
printf("Here's child process1\n");
sleep(20);
} else {
printf("the child process pid is %d\n", pid);
}
} else {
sleep(40);
}
return 0;
}
This is a typical code for creating a daemon process with two forks (except I didn't write the SIGCHLD handling). Let's look at the output of this code.

We can see that the PID of the daemon process is 449920.
Then we execute the ps -efj and ps auf commands to check the results.

We can see that the process 449920 did not get re-parented to the init process of the current namespace after the parent process exited. Why is that? Perhaps some keen-eyed readers have noticed a special syscall in this code: prctl8. We set the current process with the PR_SET_CHILD_SUBREAPER attribute.
Now let's look at the implementation in the kernel.
/*
* When we die, we re-parent all our children, and try to:
* 1. give them to another thread in our thread group, if such a member exists
* 2. give it to the first ancestor process which prctl'd itself as a
* child_subreaper for its children (like a service manager)
* 3. give it to the init process (PID 1) in our pid namespace
*/
static struct task_struct *find_new_reaper(struct task_struct *father,
struct task_struct *child_reaper)
{
struct task_struct *thread, *reaper;
thread = find_alive_thread(father);
if (thread)
return thread;
if (father->signal->has_child_subreaper) {
unsigned int ns_level = task_pid(father)->level;
/*
* Find the first ->is_child_subreaper ancestor in our pid_ns.
* We can't check reaper != child_reaper to ensure we do not
* cross the namespaces, the exiting parent could be injected
* by setns() + fork().
* We check pid->level, this is slightly more efficient than
* task_active_pid_ns(reaper) != task_active_pid_ns(father).
*/
for (reaper = father->real_parent;
task_pid(reaper)->level == ns_level;
reaper = reaper->real_parent) {
if (reaper == &init_task)
break;
if (!reaper->signal->is_child_subreaper)
continue;
thread = find_alive_thread(reaper);
if (thread)
return thread;
}
}
return child_reaper;
}
Here we summarize that when the parent process exits, its child processes will be re-parented in the following order:
-
The remaining available threads in the thread group (these threads are somewhat different; we can temporarily ignore this).
-
Continuously search for processes that have set PR_SET_CHILD_SUBREAPER in the current process tree.
-
If neither of the above two is effective, re-parent to the init process (PID 1) in the current PID Namespace.
At this point, we have completed the basic introduction to process management in Linux. Now, let's discuss the situation in containers.
The Init Process in Containers#
Here, we will use Docker as a background to discuss this topic. First, after Docker version 1.11, its architecture underwent significant changes, as shown in the image below.

The process of starting a container is as follows:
-
The Docker Daemon sends instructions to containerd.
-
containerd creates a containerd-shim process.
-
containerd-shim creates a runc process.
-
The runc process sets up the environment according to the OCI standards (creating cgroups, creating namespaces, etc.) and then executes the command specified in the
entrypoint. -
After runc completes the related setup, it exits itself, at which point its child process (the init process in the container namespace) will be re-parented to the containerd-shim process.
OK, the operation in step 5 relies on the prctl and PR_SET_CHILD_SUBREAPER we discussed in the previous section.
Thus, containerd-shim will take on the responsibility of managing processes within the container, even if its parent process exits, the child processes will be managed according to the re-parenting process to the containerd-shim process.
So, does this mean there are no issues?
The answer is clearly no. Let me give you a practical scenario: suppose I have a service that needs to implement a graceful shutdown. Generally, we would use the SIGTERM signal to achieve this before forcefully killing the process. However, in the container scenario, there is a problem: our init process may not be the program itself (for example, people often consider wrapping it in bash in the entrypoint), or in some special cases, all processes in the container have already been managed by containerd-shim. And containerd-shim does not have the capability to forward signals.
Therefore, in such scenarios, we need to consider introducing additional components to fulfill our requirements. Here, I will introduce a very lightweight init process project designed specifically for containers called tini9.
Let's take a look at some of the core code.
int register_subreaper () {
if (subreaper > 0) {
if (prctl(PR_SET_CHILD_SUBREAPER, 1)) {
if (errno == EINVAL) {
PRINT_FATAL("PR_SET_CHILD_SUBREAPER is unavailable on this platform. Are you using Linux >= 3.4?")
} else {
PRINT_FATAL("Failed to register as child subreaper: %s", strerror(errno))
}
return 1;
} else {
PRINT_TRACE("Registered as child subreaper");
}
}
return 0;
}
int wait_and_forward_signal(sigset_t const* const parent_sigset_ptr, pid_t const child_pid) {
siginfo_t sig;
if (sigtimedwait(parent_sigset_ptr, &sig, &ts) == -1) {
switch (errno) {
case EAGAIN:
break;
case EINTR:
break;
default:
PRINT_FATAL("Unexpected error in sigtimedwait: '%s'", strerror(errno));
return 1;
}
} else {
/* There is a signal to handle here */
switch (sig.si_signo) {
case SIGCHLD:
/* Special-cased, as we don't forward SIGCHLD. Instead, we'll
* fallthrough to reaping processes.
*/
PRINT_DEBUG("Received SIGCHLD");
break;
default:
PRINT_DEBUG("Passing signal: '%s'", strsignal(sig.si_signo));
/* Forward anything else */
if (kill(kill_process_group ? -child_pid : child_pid, sig.si_signo)) {
if (errno == ESRCH) {
PRINT_WARNING("Child was dead when forwarding signal");
} else {
PRINT_FATAL("Unexpected error when forwarding signal: '%s'", strerror(errno));
return 1;
}
}
break;
}
}
return 0;
}
Here we can clearly see two core points:
-
Tini will use prctl and PR_SET_CHILD_SUBREAPER to take over orphan processes within the container.
-
Tini will forward signals to child processes or the associated process group upon receiving signals.
Of course, Tini itself also has some minor issues (though they are relatively obscure). Here’s a discussion topic: suppose we have a service that creates 10 daemon processes and then exits itself. In these ten daemon processes, we set a completely new process group ID (what is known as process group escape). How do we forward signals to these ten processes? (Just for discussion; anyone doing this in production would have been severely reprimanded).
Conclusion#
By now, some may criticize me for not sticking to the topic, as I spent a large portion discussing Linux processes instead of the init process in containers.
In fact, traditional containers can essentially be regarded as a complete process running within the OS. Discussing the init process in containers cannot be separated from discussing relevant knowledge points in Linux process management.
I hope this technical article helps everyone gain a general understanding of the init process in containers and enables correct usage and management of it.
Finally, I wish everyone a Happy New Year! (I hope I won't have to rely on writing articles for a living in the new year, sob sob sob).
Reference#
- [1]. Docker
- [2]. containerd
- [3]. kata
- [4]. task_struct
- [5]. Linux Man Page: fork
- [9]. tini