これは 2021 年の最後の記事(旧正月)かもしれませんし、2022 年の最初の記事かもしれませんが、これは私がいつ書き終えるかに完全に依存します。今回は Linux におけるネットワーク監視について簡単に話しましょう。
はじめに#
この記事は水文でありながら、水文ではありません。しかし、初心者向けの記事です。この文章は実際には私のドラフトボックスに 1 年以上も滞在しており、最初のインスピレーションは私がアリババでのいくつかの仕事から得たものです(ある意味では国内で先駆的な(しかし比較的小規模な)仕事です(XD)。
技術の進展に伴い、皆さんはサービスの安定性に対する要求がますます高まっています。そして、サービス品質を保証する前提条件は、適切な監視のカバレッジを持つことです(アリババのサービス安定性に対する要求は「1-5-10」と呼ばれ、1 分で発見、5 分で処理、10 分で自己修復というものです。このような安定性の要求に対して十分なカバレッジを持つ監視がなければ、すべては無意味です)。その中でも、ネットワーク品質の監視は最も重要です。
ネットワーク品質の監視について議論する前に、ネットワーク品質という定義のカバレッジ範囲を明確にする必要があります。
- ネットワークリンク上の異常状況
- サーバー側のネットワーク処理能力
このようなカバレッジ範囲を明確にした後、どのような指標がネットワーク品質の低下を示すかを考えることができます。(注:この記事では主に TCP および TCP 上のプロトコルの監視を分析しますので、以降は詳述しません)
- 疑いなく、パケットロスが発生している場合
- 送信 / 受信キューのブロッキング
- タイムアウト
では、具体的な詳細を見てみましょう。
- RFC7931で提案された RTO や、RFC62982で提案された再送タイマーなどの指標は、パケット送信時間を測定できます。大まかに言えば、これらの指標が大きいほどネットワーク品質が低下していることを示します。
- RFC20183で提案された SACK について、不正確な概括をすると、SACK が多いほどパケットロスが多いことを示します。
- リンクが頻繁に RST される場合も、ネットワーク品質に問題があることを示します。
もちろん、実際の生産プロセスでは、他にも多くの指標を用いてネットワーク品質を補助的に測定できますが、この記事では主にプロトタイプの考え方を紹介するため、詳細には触れません。
この記事で取得したい指標が明確になったら、次にこれらの指標をどのように取得するかを分析します。
カーネルネットワーク品質監視#
バイオレンス版#
カーネルからネットワークのメトリックを取得することは、本質的にはカーネルから実行状態を取得することです。この点について、Linux に詳しい方は最初にThe Proc Filesystem4を見て、具体的な指標が取得できるかどうかを確認することを考えるでしょう。はい、良い考えです。実際に一部の指標を取得できます(これがnetstatなどのいくつかのネットワークツールの原理です)。
/proc/net/tcpでは、カーネルが吐き出すメトリックを取得できます。現在、以下のような情報が含まれています。
- 接続状態
- ローカルポート、アドレス
- リモートポート、アドレス
- 受信キューの長さ
- 送信キューの長さ
- スロースタートの閾値
- RTO 値
- 接続に属するソケットの inode ID
- UID
- 遅延 ACK ソフトクロック
完全な説明はproc_net_tcp.txt5を参照してください。
この方法はプロトタイプには適しているかもしれませんが、いくつかの固有の欠点が生産での大規模使用を制限しています。
- カーネルはproc_net_tcp.txt5の使用を明確に推奨していません。言い換えれば、将来の互換性とメンテナンスは保証されていません。
- カーネルが直接提供するメトリック情報はまだ少なく、RTT や SRTT のような指標は取得できず、SACK などの特定のイベントも取得できません。
- カーネルが出力するメトリックには、リアルタイム性と精度の問題があります。言い換えれば、精度を考慮しない場合にはこの分野での試みが可能です。
- proc_net_tcp.txt5はネットワーク名前空間にバインドされています。言い換えれば、コンテナのシナリオでは、存在する可能性のある複数のネットワーク名前空間を遍歴し、
nsenterを使用して対応するメトリックを取得する必要があります。
このような背景の下で、proc_net_tcp.txt5は大規模な使用シナリオにはあまり適していません。したがって、さらなる最適化が必要です。
最適化 1.0 版#
前述のように、The Proc Filesystem4からデータを直接取得することの欠点について言及しました。その中で重要な点は次のように述べられています。
カーネルはproc_net_tcp.txt5の使用を明確に推奨していません。言い換えれば、将来の互換性とメンテナンスは保証されていません。
では、推奨される方法は何でしょうか?答えはnetlink+sock_diagです。
簡単に説明すると、netlink6は Linux 2.2 で導入されたカーネル空間とユーザー空間間の通信メカニズムで、最初に RFC35497で提案されました。公式の netlink6に関する説明は次のようになります。
Netlink は、カーネルとユーザープロセス間で情報を転送するために使用されます。ユーザープロセス用の標準的なソケットベースのインターフェースと、カーネルモジュール用の内部カーネル API で構成されています。内部カーネルインターフェースはこのマニュアルページには文書化されていません。また、netlink キャラクタデバイスを介した古い netlink インターフェースもあります。このインターフェースはここでは文書化されておらず、後方互換性のためだけに提供されています。
簡単に言えば、ユーザーは netlink6を利用してカーネル内のさまざまなカーネルモジュールとデータを簡単にやり取りできます。
このようなシナリオでは、sock_diag8を利用する必要があります。公式の説明は次のようになります。
sock_diag netlink サブシステムは、カーネルからさまざまなアドレスファミリのソケットに関する情報を取得するためのメカニズムを提供します。このサブシステムは、個々のソケットに関する情報を取得したり、ソケットのリストを要求したりするために使用できます。
ここで言いたいのは、sock_diag7を利用して異なるソケットの接続状態や関連する指標を取得できるということです。(前述のすべての指標を取得でき、より詳細な RTT などの指標も取得できます)。あ、そうそう、ここで注意が必要なのは、netlink6を使用すると、パラメータを設定してすべてのネットワーク名前空間から指標を取得できることです。
netlink6を使用する際、純粋な C で書くのは比較的面倒です。幸いなことに、コミュニティには多くの成熟したライブラリが封装されています。ここでは、vishvananda が封装した netlink ライブラリ8を選び、デモを示します。
package main
import (
"fmt"
"github.com/vishvananda/netlink"
"syscall"
)
func main() {
results, err := netlink.SocketDiagTCPInfo(syscall.AF_INET)
if err != nil {
return
}
for _, item := range results {
if item.TCPInfo != nil {
fmt.Printf("Source:%s, Dest:%s, RTT:%d\n", item.InetDiagMsg.ID.Source.String(), item.InetDiagMsg.ID.Destination.String(), item.TCPInfo.Rtt)
}
}
}
実行例は次のようになります。
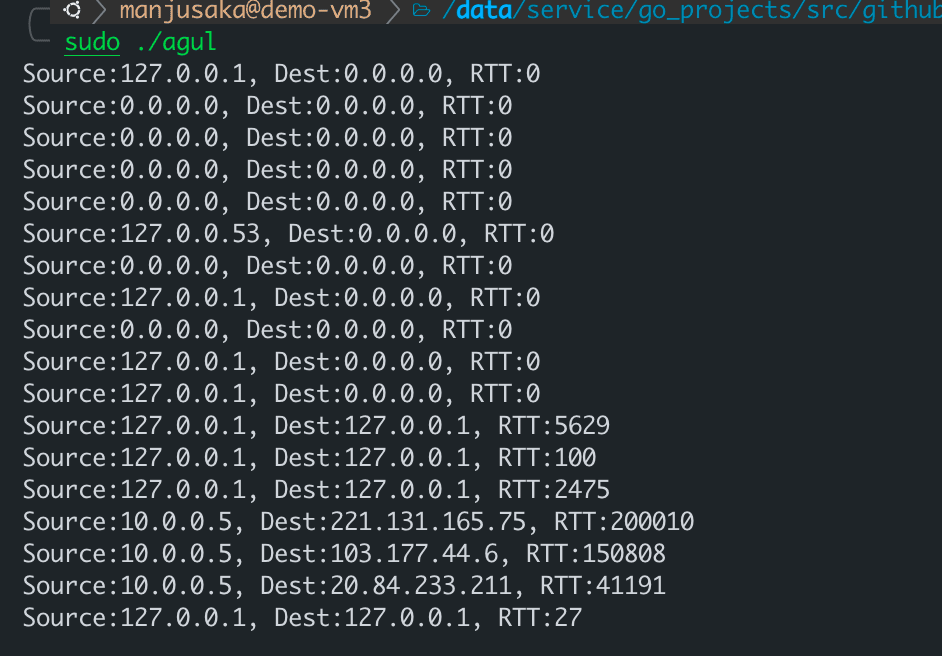
OK、これで公式に推奨されるベストプラクティスを使用して、より完全で詳細な指標を取得でき、ネットワーク名前空間の問題を心配する必要はありませんが、最初のいくつかの問題にはまだ厄介なものがあります。それはリアルタイム性の問題です。
なぜなら、周期的にポーリングを選択すると、ポーリング間隔中にネットワークの変動が発生した場合、対応する現場を失うことになるからです。では、リアルタイム性の問題をどのように解決するのでしょうか?
最適化 2.0 版#
再送や接続リセットなどのイベントが発生したときに、直接呼び出しをトリガーする必要があります。私の以前のブログを読んだことがある方は、最初に eBPF + kprobe の組み合わせを考えるかもしれません。tcp_resetやtcp_retransmit_skbなどの重要な呼び出しにポイントを打ってリアルタイムデータを取得するのは良い考えです。いいですね!
しかし、実際にはいくつかの小さな問題があります。
- kprobe のオーバーヘッドは高頻度の場合、比較的大きくなります。
- もし私たちが単に source_address、dest_address、source_port、dest_port などの情報が必要なだけなら、kprobe を使って完全な skb を取得し、キャストするのは実際には少し無駄です。
では、もっと良い方法はありますか?あります!
Linux には、私たちのニーズに似た特殊なイベントのトリガーとコールバックのための基盤となるインフラストラクチャがあり、それを Tracepoint9と呼びます。このインフラストラクチャは、イベントをリスンし、コールバックするニーズをうまく処理できます。そして、Linux 4.15 および 4.16 以降、Linux は 6 つの TCP 関連の Tracepoint9を追加しました。
それぞれは次の通りです。
- tcp
- tcp
- tcp
- tcp
- tcp
- tcp
これらの Tracepoint9の意味は、名前を見ればわかるでしょう。
これらの Tracepoint9がトリガーされると、登録されたコールバック関数にいくつかのパラメータが渡されます。ここで、リストを示します。
tcp:tcp_retransmit_skb
const void * skbaddr;
const void * skaddr;
__u16 sport;
__u16 dport;
__u8 saddr[4];
__u8 daddr[4];
__u8 saddr_v6[16];
__u8 daddr_v6[16];
tcp:tcp_send_reset
const void * skbaddr;
const void * skaddr;
__u16 sport;
__u16 dport;
__u8 saddr[4];
__u8 daddr[4];
__u8 saddr_v6[16];
__u8 daddr_v6[16];
tcp:tcp_receive_reset
const void * skaddr;
__u16 sport;
__u16 dport;
__u8 saddr[4];
__u8 daddr[4];
__u8 saddr_v6[16];
__u8 daddr_v6[16];
tcp:tcp_destroy_sock
const void * skaddr;
__u16 sport;
__u16 dport;
__u8 saddr[4];
__u8 daddr[4];
__u8 saddr_v6[16];
__u8 daddr_v6[16];
tcp:tcp_retransmit_synack
const void * skaddr;
const void * req;
__u16 sport;
__u16 dport;
__u8 saddr[4];
__u8 daddr[4];
__u8 saddr_v6[16];
__u8 daddr_v6[16];
tcp:tcp_probe
__u8 saddr[sizeof(struct sockaddr_in6)];
__u8 daddr[sizeof(struct sockaddr_in6)];
__u16 sport;
__u16 dport;
__u32 mark;
__u16 length;
__u32 snd_nxt;
__u32 snd_una;
__u32 snd_cwnd;
__u32 ssthresh;
__u32 snd_wnd;
__u32 srtt;
__u32 rcv_wnd;
ここまで来ると、皆さんはおおよそのことがわかるでしょう。それでは、サンプルコードを書いてみましょう。
from bcc import BPF
bpf_text = """
BPF_RINGBUF_OUTPUT(tcp_event, 65536);
enum tcp_event_type {
retrans_event,
recv_rst_event,
};
struct event_data_t {
enum tcp_event_type type;
u16 sport;
u16 dport;
u8 saddr[4];
u8 daddr[4];
u32 pid;
};
TRACEPOINT_PROBE(tcp, tcp_retransmit_skb)
{
struct event_data_t event_data={};
event_data.type = retrans_event;
event_data.sport = args->sport;
event_data.dport = args->dport;
event_data.pid=bpf_get_current_pid_tgid()>>32;
bpf_probe_read_kernel(&event_data.saddr,sizeof(event_data.saddr), args->saddr);
bpf_probe_read_kernel(&event_data.daddr,sizeof(event_data.daddr), args->daddr);
tcp_event.ringbuf_output(&event_data, sizeof(struct event_data_t), 0);
return 0;
}
TRACEPOINT_PROBE(tcp, tcp_receive_reset)
{
struct event_data_t event_data={};
event_data.type = recv_rst_event;
event_data.sport = args->sport;
event_data.dport = args->dport;
event_data.pid=bpf_get_current_pid_tgid()>>32;
bpf_probe_read_kernel(&event_data.saddr,sizeof(event_data.saddr), args->saddr);
bpf_probe_read_kernel(&event_data.daddr,sizeof(event_data.daddr), args->daddr);
tcp_event.ringbuf_output(&event_data, sizeof(struct event_data_t), 0);
return 0;
}
"""
bpf = BPF(text=bpf_text)
def process_event_data(cpu, data, size):
event = bpf["tcp_event"].event(data)
event_type = "retransmit" if event.type == 0 else "recv_rst"
print(
"%s %d %d %s %s %d"
% (
event_type,
event.sport,
event.dport,
".".join([str(i) for i in event.saddr]),
".".join([str(i) for i in event.daddr]),
event.pid,
)
)
bpf["tcp_event"].open_ring_buffer(process_event_data)
while True:
bpf.ring_buffer_consume()
ここでは、tcp_receive_resetとtcp_retransmit_skbを使用して、私たちのマシン上のプログラムを監視しています。具体的な効果を示すために、まず Go で Google にアクセスするプログラムを書き、その後sudo iptables -I OUTPUT -p tcp -m string --algo kmp --hex-string "|c02bc02fc02cc030cca9cca8c009c013c00ac014009c009d002f0035c012000a130113021303|" -j REJECT --reject-with tcp-resetを使用してこの Go プログラムに接続リセットを注入しました(ここでの注入原理は、Go のデフォルトライブラリが発起する HTTPS リンクの Client Hello 特徴が固定されているため、iptables が流量の方向を認識し、リンクをリセットします)。
効果は次の通りです。

ここまで書くと、Tracepoint9と netlink6を組み合わせてリアルタイム性のニーズを満たすことができることがわかります。
最適化 3.0 版#
実際、ここまで書いてきたのは、プロトタイプや思考の紹介が主です。生産上のニーズを満たすためには、まだ多くの作業が必要です(これも私が以前行っていた作業の一部です)。これには、次のようなことが含まれますが、これに限定されません。
- エンジニアリング上のパフォーマンス最適化、サービスへの影響を避ける
- Kubernetes などのコンテナプラットフォームとの互換性
- Prometheus などのデータ監視プラットフォームとの連携
- より簡便な監視パスを取得するために CNI を埋め込む必要があるかもしれません。
実際、コミュニティには Cilium など、非常に興味深い作業がたくさんあります。興味がある方はぜひ注目してください。また、私も後でコードを整理し、適切なタイミングで以前の実装パスをオープンソースにする予定です。
まとめ#
この記事はここまでです。カーネルのネットワーク監視は比較的小規模な分野です。私の経験が皆さんの助けになることを願っています。では、皆さん、明けましておめでとうございます!虎年が幸運でありますように!(次の記事は昨年の年末総括を書く予定です)
参考文献#
- RFC793: https://datatracker.ietf.org/doc/html/rfc793
- RFC6298: https://datatracker.ietf.org/doc/html/rfc6298
- RFC2018: https://datatracker.ietf.org/doc/html/rfc2018
- The /proc Filesystem: https://www.kernel.org/doc/html/latest/filesystems/proc.html
- proc_net_tcp.txt: https://www.kernel.org/doc/Documentation/networking/proc_net_tcp.txt
- netlink: https://man7.org/linux/man-pages/man7/netlink.7.html
- sock_diag: https://man7.org/linux/man-pages/man7/sock_diag.7.html
- vishvananda/netlink: https://github.com/vishvananda/netlink
9: Linux Tracepoint: https://www.kernel.org/doc/html/latest/trace/tracepoints.html