今日は興味深い問題に遭遇しました。「nohdr フィールドは実際にはどのように使用されるのか」という問題です。ここに簡単な水文を書いて記録しておきます。
本文#
前提条件#
まず、どれほどマイナーなフィールドを紹介しても、SKBUFF に関連する場合は、まず sk_buff について簡単に説明する必要があります。
要するに、sk_buff は Linux ネットワークサブシステムの中核データ構造であり、リンク層からデータパケットの最終的な操作まで、すべての操作は sk_buff なしでは行えません。
sk_buff を完全に説明することは、基本的には Linux ネットワークシステム全体を説明することに等しいため、完全に説明することは不可能です。この人生では絶対に不可能です!
いくつかの重要なポイントについて簡単に話しましょう。これらは、本文で言及されているマイナーフィールド nohdr の重要なフィールドを理解するのに役立つかもしれません。
まず最も重要な 3 つのフィールドは、data、mac、およびnhです。それぞれ、現在の sk_buff のデータ領域の開始アドレス、L2 ヘッダの開始アドレス、L3 ヘッダの開始アドレスを表します。図を使って理解しやすくします。
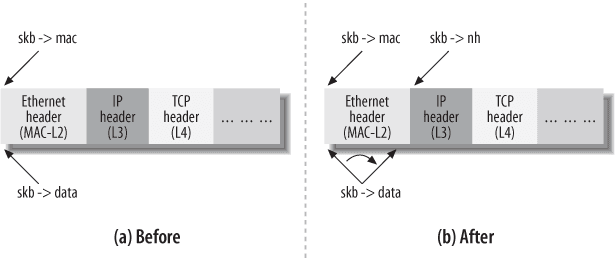
図を見た人は少し理解できるかもしれません。実際には、カーネル内部でも、ネットワークリクエストを処理するために、ポインタのオフセットを使用してヘッダを追加していくという方法で、段階的にヘッダを追加しています。これは私たちの直感と一致しています。おそらく、L3 ヘッダの開始アドレスを知っているのであれば、IP などの L3 プロトコルのヘッダの長さを計算し、手動で処理できるのではないかと思うかもしれません。
Bingo、カーネル内部にはtcphdrというデータ構造があります(IP に対応するのはiphdrです)。オフセットに基づいて、手動でキャストすることで手動で処理できます。ただし、詳細な手順については後で話しましょう。
次に、2 つの重要なフィールドがあります。それはlenとdata_lenです。これらのフィールドはどちらもデータの長さを示していますが、簡単に言えば、len は現在の sk_buff のすべてのデータの長さを表し(つまり、現在のプロトコルのヘッダとペイロードを含む)、data_len は現在の有効なデータの長さを表します(つまり、現在のプロトコルのペイロードの長さ)。
OK、前提条件はここまでです。
nohdr について#
花は 2 つ咲き、それぞれが 1 本の枝を表します。sk_buff のいくつかの事前知識について話した後、nohdrというフィールドについて話しましょう。正直なところ、このフィールドは本当にマイナーです。
まず、公式には次のように説明されています。
'nohdr' フィールドは TCP セグメンテーションオフロード('TSO' と略される)のサポートに使用されます。この機能をサポートするほとんどのデバイスは、パケットスニッファなどに変更が見えないように、送信パケットの TCP および IP ヘッダにいくつかの細微な変更を加える必要があります。したがって、これらの変更がパケットスニッファなどに表示されないようにするために、この「nohdr」フィールドとデータ領域の参照カウントの特別なビットを使用して、デバイスがパケットヘッダの変更を行う前にデータ領域を置き換える必要があるかどうかを追跡します。
うーん、この段落は少しわかりにくいです。まず、TSO については皆さんが一定の理解を持っているはずです。ネットワークカードを使用して大きなデータパケットをセグメント化するためのものです(具体的な Linux の GSO/TSO の実装については、別の記事で詳しく説明します)。この場合、ネットワークカードはヘッダの一部を少し変更してパケットのセグメント化を完了する必要がある場合があります。
しかし、L4 レイヤのパケットに関しては、ヘッダの変更には関心がなく、ペイロードに関心がある場合があります。では、どうすればいいのでしょうか。ここで「nohdr」が役立ちます。
ここで、「nohdr」が有効になるためには、別のフィールド「dataref」と組み合わせる必要があります。datarefはカウンタフィールドであり、具体的には、現在のデータフィールドが何個の sk_buff によって参照されているかを示します。ここには 2 つのケースがあります。
- nohdr が 0 の場合、dataref の値はデータ領域の参照カウントです。
- nohdr が 1 の場合、上位 16 ビットはペイロードデータ領域の参照カウントであり、下位 16 ビットはデータ領域の参照カウントです。
公式には次のように説明されています。
/* We divide dataref into two halves. The higher 16 bits hold references * to the payload part of skb->data. The lower 16 bits hold references to * the entire skb->data. It is up to the users of the skb to agree on * where the payload starts.
* * All users must obey the rule that the skb->data reference count must be * greater than or equal to the payload reference count.
* * Holding a reference to the payload part means that the user does not * care about modifications to the header part of skb->data.
*/
#define SKB_DATAREF_SHIFT 16 #define SKB_DATAREF_MASK ((1 << SKB_DATAREF_SHIFT) - 1)
実際には、なぜこのように設計されたのかはあまり難しくありません。まず、カーネル内部でパケットを取得する場合、ヘッダの具体的な内容には関心がなく、ペイロードに関心がある場合があります。また、ペイロードの参照カウントについても、正確性を保証するために個別に処理する必要があります。これにより、データがまだ処理されていない場合に、データスライスがカーネルによって事前に解放されないようになります。もちろん、この領域を処理する際には、データ領域の参照カウントがペイロードの参照カウントよりも大きいことを確認する必要があります(これは約束を守らないと、カーネルがダンプされる結果になるかもしれません)。
最後に、カーネルはデータ領域のメモリスペースを適切なタイミングで解放するために、dataref を使用します。解放条件は次のいずれかを満たす必要があります。
- !skb->cloned: skb がクローンされていない場合
- !atomic_sub_return (skb->nohdr ? (1 << SKB_DATAREF_SHIFT) + 1 : 1, &skb_shinfo (skb)->dataref)、つまり、nohdr が 1 の場合は dataref-(1 << SKB_DATAREF_SHIFT) + 1) を使用してデータ領域を解放する必要があるかどうかを判断します。nohdr が 0 の場合は dataref-1 を使用してデータ領域を解放する必要があります。
まとめ#
水文はだいたいこんな感じです。「nohdr」は本当にマイナーなフィールドです。この水文のいくつかの参照は電車の中で調べたものですので、記事には書いていません。だいたいこんな感じです。問題を解くために戻ります。