Today I encountered an interesting question, "What is the use of the 'nohdr' field in sk_buff?" I will write a brief discussion about it here.
Main Content#
Background#
First of all, regardless of how obscure a field may be, since it involves SKBUFF, we need to provide a brief introduction to sk_buff.
In short, sk_buff is the core data structure of the Linux networking subsystem. From the link layer to our final operations on packets, sk_buff is always involved.
Explaining sk_buff in its entirety is essentially equivalent to explaining the entire Linux networking system, so it is impossible to cover everything in one discussion.
Let's briefly discuss a few key points that may help you understand the obscure field mentioned in this article.
Firstly, let's talk about the three most important fields: data, mac, and nh, which respectively represent the starting addresses of the data area, the L2 header, and the L3 header of the current sk_buff. Here's a diagram to help you understand:
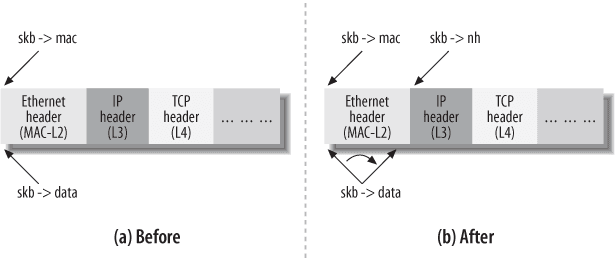
After looking at the diagram, you may have some understanding. In the kernel, new headers are added layer by layer through pointer offsets to process network requests. This aligns with our intuition. You may ask, since I know the starting address of the L3 header, can't I calculate the offset of L4 and manually process it?
Bingo! In the kernel, there is a data structure called tcphdr (corresponding to iphdr for IP). You can manually process it by casting based on the offset. However, we will discuss the detailed approach another time.
Next, let's talk about two important fields: len and data_len. Both of these fields indicate the length of the data, but briefly, len represents the total length of all data in the sk_buff (including the headers and payload of the current protocol), while data_len represents the length of the current valid data (i.e., the length of the payload of the current protocol).
OK, that's the background.
About nohdr#
Two flowers bloom, each showing its own beauty. After discussing some background knowledge about sk_buff, let's talk about the nohdr field. To be honest, this field is really obscure.
First, there is an official description of it:
The 'nohdr' field is used in the support of TCP Segmentation Offload ('TSO' for short). Most devices supporting this feature need to make some minor modifications to the TCP and IP headers of an outgoing packet to get it in the right form for the hardware to process. We do not want these modifications to be seen by packet sniffers and the like. So we use this 'nohdr' field and a special bit in the data area reference count to keep track of whether the device needs to replace the data area before making the packet header modifications.
Hmm, this paragraph is a bit convoluted. First of all, I'm sure most people are familiar with TSO. It uses the network card to segment large packets (the implementation of GSO/TSO under Linux can be discussed in another article). In this case, the network card may need to make some minor modifications to the header to perform the segmentation operation.
However, sometimes we don't need to care about the modified header of the L4 layer of a packet, we only need to focus on its payload. So how do we handle this? This is where the nohdr field comes into play.
Here, the effectiveness of nohdr also requires another field, dataref. dataref is a counter field that specifically refers to how many sk_buffs reference the data area pointed to by the data field. There are two situations here:
- When
nohdris 0, the value ofdatarefrepresents the reference count of the data area. - When
nohdris 1, the higher 16 bits represent the reference count of the payload data area, and the lower 16 bits represent the reference count of the data area.
The official description is as follows:
/* We divide dataref into two halves. The higher 16 bits hold references * to the payload part of skb->data. The lower 16 bits hold references to * the entire skb->data. It is up to the users of the skb to agree on * where the payload starts.
* * All users must obey the rule that the skb->data reference count must be * greater than or equal to the payload reference count.
* * Holding a reference to the payload part means that the user does not * care about modifications to the header part of skb->data.
*/
#define SKB_DATAREF_SHIFT 16 #define SKB_DATAREF_MASK ((1 << SKB_DATAREF_SHIFT) - 1)
Actually, it is not difficult to understand why it is designed this way. First of all, when we retrieve packets in the kernel, sometimes we don't need to care about the specific headers, only the payload. We also need to handle the reference count of the payload separately to ensure its correctness. This ensures that the data will not be released by the kernel before we finish processing it. Of course, when working on this, you need to ensure that the reference count of the data area is greater than the reference count of the payload (it feels like a "convention over configuration" approach? Of course, not following this convention will result in a kernel dump, haha).
Finally, our kernel also uses dataref to release the memory space of the data area at the appropriate time. The release conditions are as follows:
- !skb->cloned: the skb is not cloned.
- !atomic_sub_return(skb->nohdr ? (1 << SKB_DATAREF_SHIFT) + 1 : 1, &skb_shinfo(skb)->dataref) In the case of
nohdrbeing 1, it determines whether the data area needs to be released bydataref - (1 << SKB_DATAREF_SHIFT) + 1. In the case ofnohdrbeing 0, it determines whether the data area needs to be released bydataref - 1.
Conclusion#
That's about it for this discussion. The nohdr field is really obscure. Well, because some of the references for this article were looked up on the subway... I'm too lazy to list them in the article... That's about it... I'm going to solve some problems now...
Translation: